
这篇文章就是记录我们如何使用python完成网络世界的爬虫任务,本次爬取内容为欧洲中心的哨兵遥感数据。哨兵遥感数据是继Landsat系列后最受欢迎的免费数据源,具有高分辨率、多光谱、精度高的种种“爆款”亮点。关于哨兵遥感数据的更多介绍这里不再复述,详情见Sentinel|Online - ESA,数据下载地址为Copernicus Open Access Hub,可以点击”Open Hub”进入数据选择主页! 该网站数据下载需要提前注册账号(很简单,自己注册即可)。
- Sentinel Online - ESA Home
-
Copernicus Open Access Hub Home
-
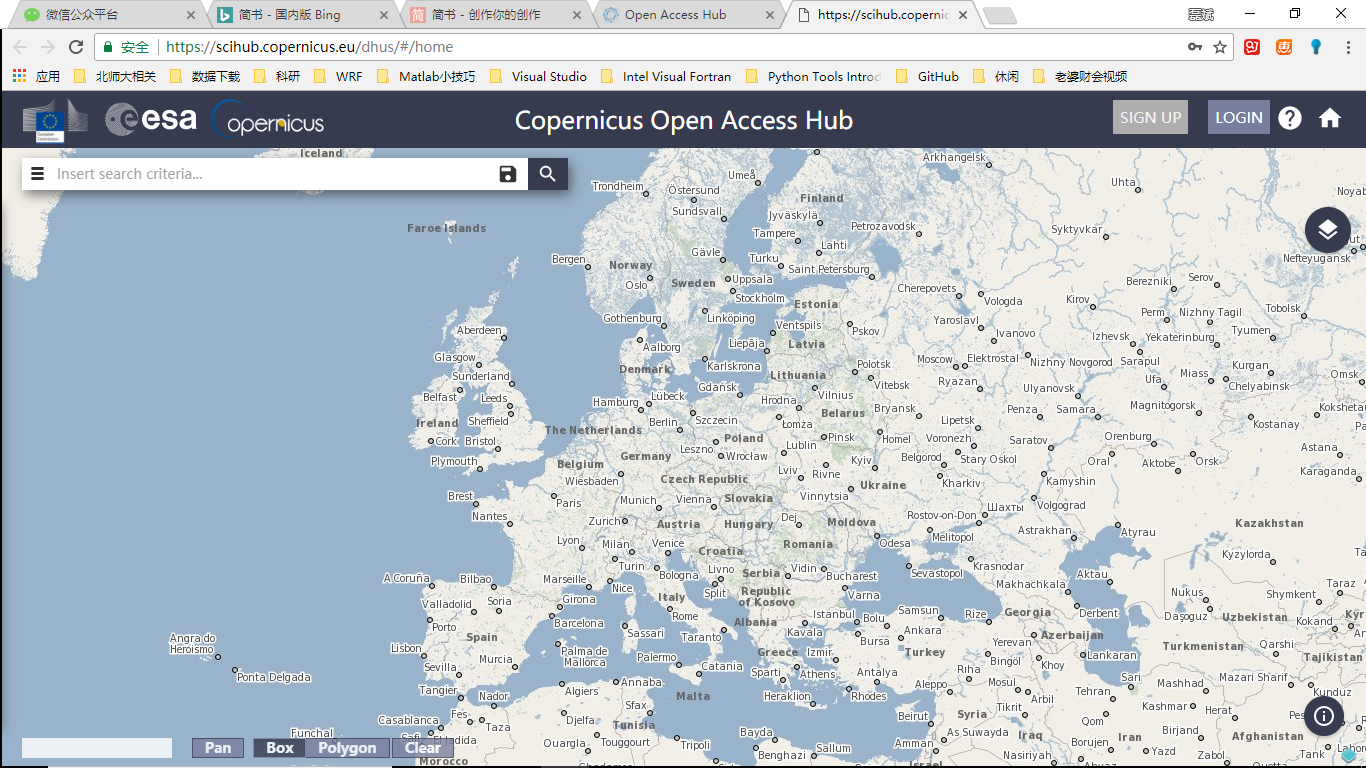
Open Access Hub Home
本次爬虫是一个简单的例子,主要用到了numpy、re、requests、BeautifulSoup模块。其中numpy主要用于存储爬取来的链接地址,re为python的正则表达式模块、requests为python的网络请求模块,BeautifulSoup是一个网页HTML、XML的解析模块。python3是大势所趋,所以本次采用的是python3.5.2版本(PS假如你采用的是Anaconda,会默认帮你配置python3环境),并且因为工作主要是在windows下进行,所以采用了Anaconda来安装python3,借助Jupyter Notebook来编写python程序。废话不多说,我们进入正题。
首先是要在python中导入我们需要的模块
import requests
import re
import numpy as np
from bs4 import BeautifulSoup as BS
from requests.auth import HTTPBasicAuth
工欲善其事,必先利其器。接下里我们要构建我们使用的函数
获取网站respond的函数
def getresp(url,params,author):
resp = requests.get(url,params=params,auth=author)
if resp.status_code == requests.codes.ok:
print('Visiting url successful!')
pass
else:
resp.raise_for_status()
# quit()
return resp
获取respond中包含的每条数据的链接
def geturl(resp):
fileurl = []
soup = BS(resp.text,'lxml')
entrys = soup.findChildren('entry')
for entry in entrys:
fileurl.append(entry.link.attrs['href'])
return fileurl
接下来时我们爬取数据时需要的用户信息等参数
填写自己的U ser Information
user = 'username' #你注册时的用户名
password = 'password' #用户名对应的登陆密码
根据用户信息构造登陆信息
author = HTTPBasicAuth(user,password)
网站的url信息,检索参数设定
- 数据检索url
url = 'https://scihub.copernicus.eu/dhus/search' - 检索结果页开始页(start,默认从0开始) and 检索结果每页记录行数(row,最大为100)
start = 0
rows = 100
- 数据检索结果排序参数(search results order)
orderby = 'beginposition desc'
参数说明: beginposition asc: sorts results by sensing date arranged in ascending order beginposition desc: sorts results by sensing date arranged in descending order ingestiondate asc: sorts results by ingestion date arranged in ascending order ingestiondate desc: sorts results by ingestion date arranged in descending order
- 检索数据的时间范围(period)
beginposition = '[2015-09-01T00:00:00.000Z TO 2017-11-14T23:59:59.999Z]'
endposition = '[2015-09-01T00:00:00.000Z TO 2017-11-14T23:59:59.999Z]'
- 遥感平台的文件名(filename)
filename = 'S2A_*'
- 遥感产品的平台名称(platformname)
platformname = 'Sentinel-2'
- 遥感产品类型(producttype)
producttype = 'S2MSI1C'
- 检索的空间范围支持polygon等,详细见下图
Search Result
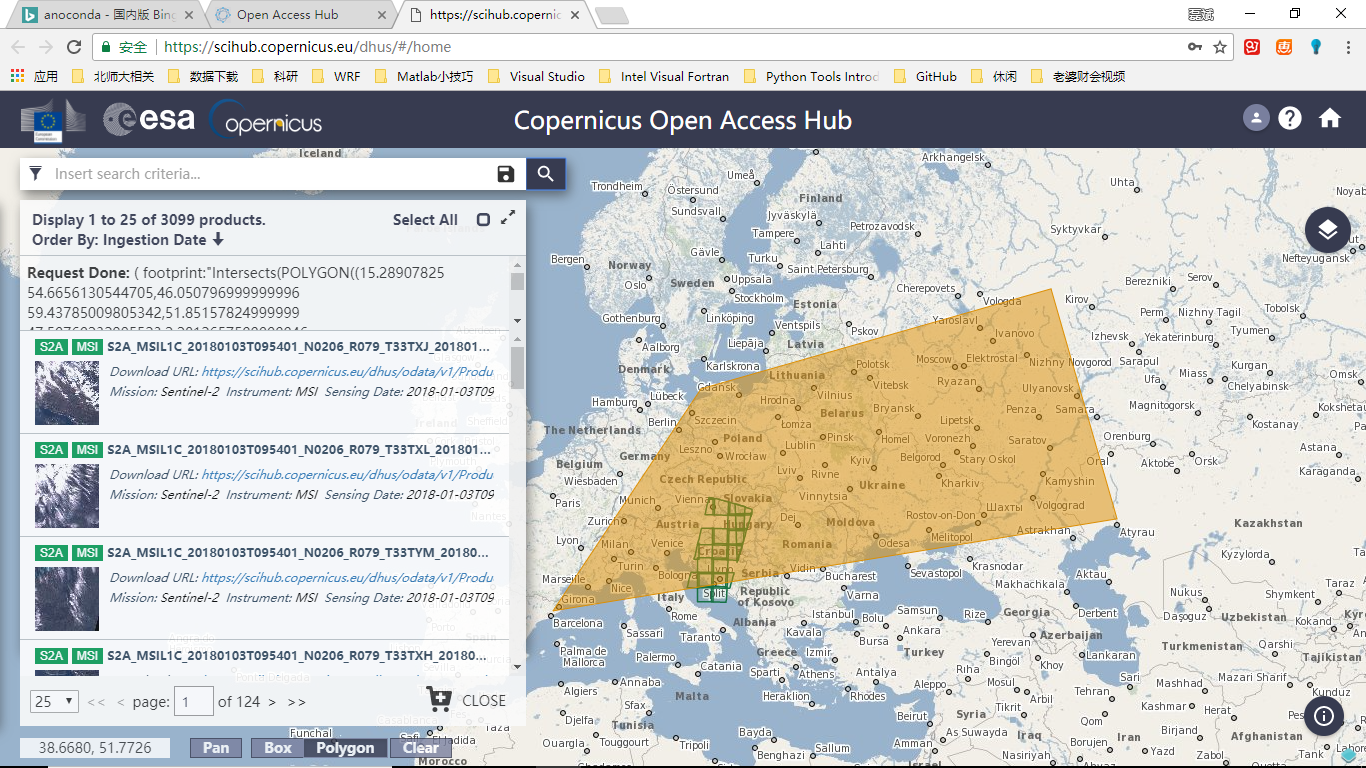 其中包含了下面构建参数的信息,以及polygon、box等空间方式
其中包含了下面构建参数的信息,以及polygon、box等空间方式
根据网站的检索参数构建检索参数表(earch parameters)
params={'q': 'footprint:"Intersects(POLYGON((-125.31488630127798 49.37923341676577,-94.1177312732597 49.611074219444475,-89.47742217298237 48.53549820848218,-88.12102412828592 48.53549820848218,-82.12431698331216 45.81890506556195,-81.33903390480367 43.37952244235831,-82.26709572485915 42.332904057015014,-79.41152089391926 42.91073956185417,-79.55429963546625 43.793199048601366,-76.91289291684686 43.84470870363458,-75.05676927673592 45.21866420479017,-71.41591136728756 45.41945598010943,-69.13145150253564 47.86937637130322,-67.27532786242472 47.3399115244641,-66.49004478391625 44.510289298419195,-68.70311527789465 43.99897102421997,-70.4878495472321 42.54364651046643,-70.63062828877908 41.26857486211881,-73.55759249049247 40.35002427915461,-75.5564948721504 37.23493437901901,-75.34232675982992 35.5106407926214,-81.26764453403018 30.91389921859202,-79.55429963546625 26.277507711359192,-80.41097208474821 24.601441451662325,-82.05292761253865 25.699976916085063,-83.40932565723509 29.246069409930726,-86.47906860049548 29.92894696853658,-89.26325406066188 29.92894696853658,-90.76243084690535 29.31312823256077,-93.47522693629823 29.31312823256077,-96.9733061041996 27.428820161771597,-96.9733061041996 25.253804342260892,-99.8288809351395 26.28243160798492,-101.32805772138293 29.188555415633374,-103.32696010304085 28.938955736789637,-104.9689156308313 29.56181780055128,-105.32586248469879 30.242555555774018,-107.5389329786772 31.40731039455048,-108.89533102337366 30.73469982619183,-113.32147201133047 31.58992129699972,-115.17759565144141 32.377092871245935,-117.39066614541981 32.377092871245935,-118.74706419011625 33.93095765190809,-120.6745772010007 34.22660464625842,-122.38792209956462 36.439439833782075,-124.52960322276952 39.97231578245231,-124.67238196431654 43.17562317292362,-124.31543511044906 47.00393239105679,-125.31488630127801 48.58637973178338,-125.31488630127798 49.37923341676577,-125.31488630127798 49.37923341676577)))"'
+ ' AND filename:'+ filename + ' AND platformname:' + platformname + ' AND producttype:' + producttype
+ ' AND beginposition:' + beginposition + ' AND endPosition:' + endposition,
'orderby': orderby,
'start': start,
'rows': rows}
准备工作都做好了,接下来该我们进行主要部分了。介于网络爬虫可能出现网络不稳定或着拒接访问的情况,所以我并没有用纯粹的python解释器来做这件事情,而是采用了Jupyter Notebook来爬虫,主要是可以查看错误原因,并且可以及其简单的实现断点重新访问。你可以尝试先在jupyter notebook中理解下面的过程或者你页可以编写一些意外处理方法使得代码更加健壮以在纯python中进行工作。
main program
- 构建一个url存储仓库
urldatabase = []
- 构建一个问题页存储仓库
wrongpages = []
- 获取检索结果信息(get search results information): start检索结果的开始数,resultnumber检索结果总数
resp = getresp(url=url,params=params,author=author)
soup = BS(resp.text,'lxml')
subtitle = soup.subtitle.contents[0]
d = re.search(r'Displaying',subtitle)
t = re.search(r'to',subtitle)
o = re.search(r'of',subtitle)
tot = re.search(r'total',subtitle)
start = int(subtitle[d.end():t.start()])
resultnumber = int(subtitle[o.end():tot.start()])
- 计算检索结果总页面数–即主循环次数
if (resultnumber%rows) == 0:
pages = resultnumber//rows
else:
pages = resultnumber//rows + 1
pages
- 下一次访问时records开始数
nextstart = start
- 设置爬虫中断后再次开始时的重新启动位置,程序初始运行时为start值
restart = start
# restart = start # 程序中断后设置重新开始位置
- main process loop
for i in range(restart,pages):
nextstart = i*rows
params={'q': 'footprint:"Intersects(POLYGON((87.96744928079151 49.456519812462346,91.60830719023988 46.83752798473412,91.25136033637239 45.602765307819425,95.89166943664972 44.64576303006464,96.7483418859317 43.15413083756209,101.46004035698249 42.94545696139997,104.8153407833369 42.156611918760944,109.95537547902869 42.94545696139997,111.38316289449862 43.827415120460785,111.09760541140463 45.000210707779814,112.16844597300711 45.50278424803122,113.73901213002404 45.201773800610084,118.80765745494234 47.37203214140084,114.80985269162649 47.75739353110845,116.52319759019043 50.28470084157169,117.95098500566037 50.01021802911433,120.52100235350628 52.467671174043375,119.30738305035682 52.68458961189609,121.09211731969427 53.71091470506266,123.94769215063415 53.79533483672091,125.94659453229207 53.2862648577391,127.94549691395 49.96431767943767,130.8010717448899 48.943405599629216,131.30079734030437 48.044555096620655,135.2272127328467 48.61410385272944,135.01304462052622 47.66131893588616,133.51386783428276 44.747256163082966,131.80052293571885 45.000210707779814,131.30079734030437 42.52598030538988,121.80601102742924 38.176115746490154,123.59074529676666 37.612756017996006,120.23544487041231 35.14161329563284,122.16295788129669 32.23150772949295,123.23379844289917 30.278766301259637,118.73626808416886 23.994003317793286,112.5253928268746 21.159899865927372,110.59787981599015 18.676749577533087,110.81204792831065 20.62633973748771,107.52813687272979 20.96003728051427,105.74340260339234 22.617193193148964,101.46004035698252 20.96003728051427,99.10419112145709 21.75786247555702,97.46223559366666 24.31969121888956,97.96196118908115 27.46602416787246,95.32055447046173 28.72552358988112,93.03609460570983 27.719103082020624,89.82357292090245 27.21236283607496,86.61105123609507 27.402663295197584,81.89935276504427 29.66033159380234,78.11571611404891 31.32119224098024,78.11571611404891 34.261260362316236,77.47321177708743 35.19996972135458,74.76041568769453 36.530544485875296,73.33262827222458 38.84644093997744,73.33262827222458 39.949730443191925,75.3315306538825 40.98163678406533,76.25959247393799 41.03550801313756,77.68737988940791 41.518365501224054,79.75767164183932 42.262367141059,80.04322912493333 43.569347922768316,79.68628227106583 45.000210707779814,81.75657402349728 45.602765307819425,82.68463584355271 47.420357376064516,84.68353822521065 47.37203214140084,87.96744928079151 49.456519812462346,87.96744928079151 49.456519812462346)))"'
+ ' AND filename:'+ filename + ' AND platformname:' + platformname + ' AND producttype:' + producttype
+ ' AND beginposition:' + beginposition + ' AND endPosition:' + endposition,
'orderby': orderby,
'start': nextstart,
'rows': rows}
resp = getresp(url=url,params=params,author=author)
urllist = geturl(resp)
if i < pages-1:
if len(urllist) == rows:
urldatabase = urldatabase + urllist
print('Page',i+1,': finished!',' ------ URL list length:',len(urllist),' ------ records numbers',len(urldatabase))
else:
print('abstract url fail!')
wrongpages.append(i+1)
else:
if len(urllist) == (resultnumber - rows * i):
urldatabase = urldatabase + urllist
print('Page',i+1,': finished!',' ------ URL list length:',len(urllist),' ------ records numbers',len(urldatabase))
else:
print('abstract url fail!')
wrongpages.append(i+1)
- 当发生中断时,查看中断页数
if i < pages - 1:
print('中断页数:',i)
else:
pass
- 查看错误页信息
wrongpages
保存爬取结果到的url
- 当我们用下载工具下载数据时同样需要用户名和密码,这里我们将其保存在url链接中
for i in range(len(urldatabase)):
a = urldatabase[i]
urldatabase[i] = a[0:8] + user + ':' + password + '@' + a[8::]
urldatabase_np = np.array(urldatabase)
- 总检索结果可能包含上万个记录,当我们用工具下载时可能想把其分成若干个任务同时下载,这里我们可以通过设置单个文件纪录长度来实现:
filelength = 1000
- 根据单个文件记录长度计算文件数:
filenumber = resultnumber//filelength + 1
- 保存爬取的检索结果到当前文件夹下
for num in range(filenumber):
if num < filenumber - 1:
np.savetxt('urls' + str(num*filelength+1) + '-' + str((num+1)*filelength) + '.txt',
urldatabase_np[num*filelength:(num+1)*filelength],fmt='%s')
else:
np.savetxt('urls' + str(num*filelength+1) + '-' + str(resultnumber) + '.txt',
urldatabase_np[num*filelength:(num+1)*filelength],fmt='%s')
至此我们就算是完成了所有遥感数据url爬取的任务,接下来你就可以用我们国内的某雷等工具来下载你想要的数据了。哨兵数据检索的重要参数请参考scihubuserguide, 我已将我的notebook上传到我的GitHub仓库欢迎参考,探讨。




